Toward Scalable Semantic Big Data
Julian Dolby
IBM Thomas J. Watson Research Center
SPLASH-I, Vancouver, October 2017
Collaborative Work
- Bishwaranjan Bhattacharjee
- Mihaela Bornea
- James Cimino
- Patrick Dantressangle
- Achille Fokoue
- Aditya Kalyanpur
- Anastasios Kementsietsidis
- Aaron Kersehbaum
- Li Ma
- Chintan Patel
- Edith Schonberg
- Kavitha Srinivas
- Octavian Udrea
Outline
- Running Example
- Scalable expressive reasoning
- Storing RDF data in a database
- Integration of Web data
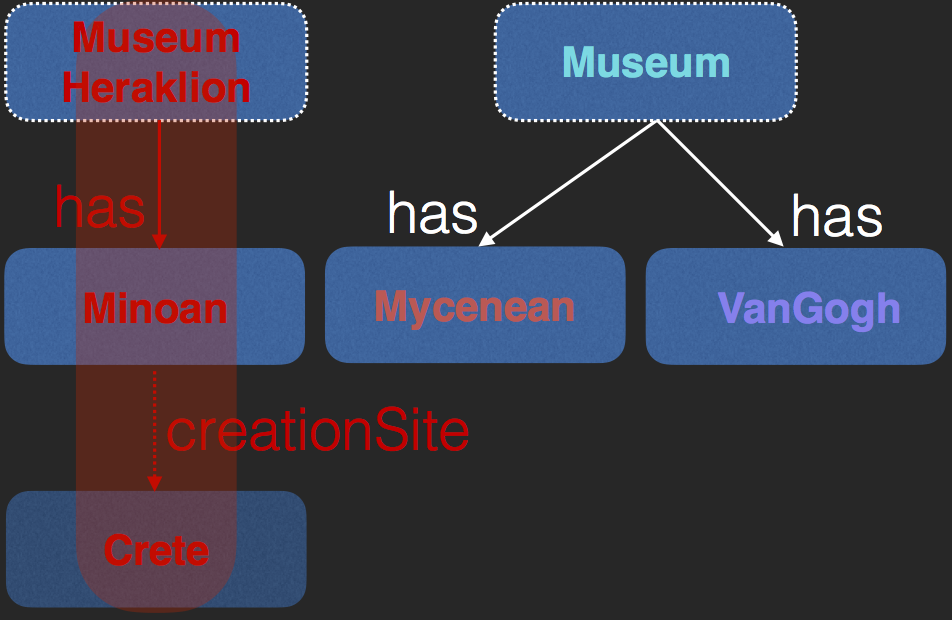
Running Example
Objects in Our Universe



Example OWL Universe
- Individuals
$\begin{array}{l}Museum(Athens), Museum(Heraklion), \\ Museum(MOMA), Minoan(LaParisienne),\\ Mycenean(DeathMask),VanGogh(StarryNight)\end{array}$ - Roles
$\begin{array}{l} has(Athens,DeathMask),has(MOMA,StarryNight)\\ has(Heraklion,LaParisienne) \end{array}$ - Axioms (TGDs)
$\begin{array}{l} Minoan \sqsubseteq \exists{creationSite.Crete}\\ Mycenaean \sqsubseteq \exists{creationSite.Mycenae} \end{array}$
Example ABox $A$
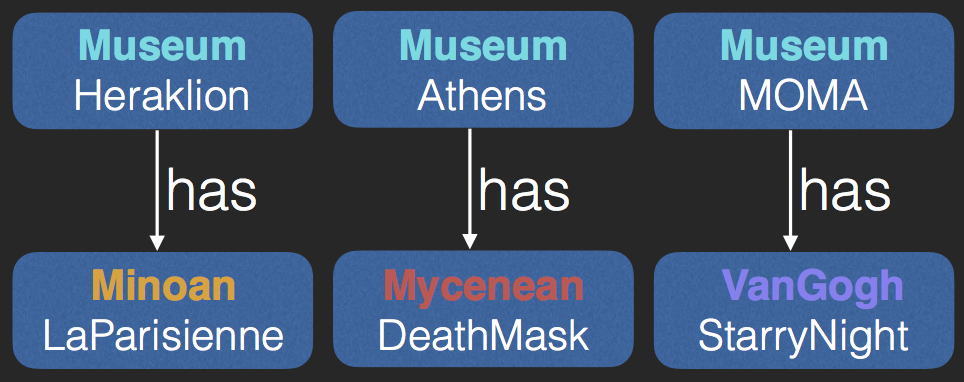
The Summary ABox
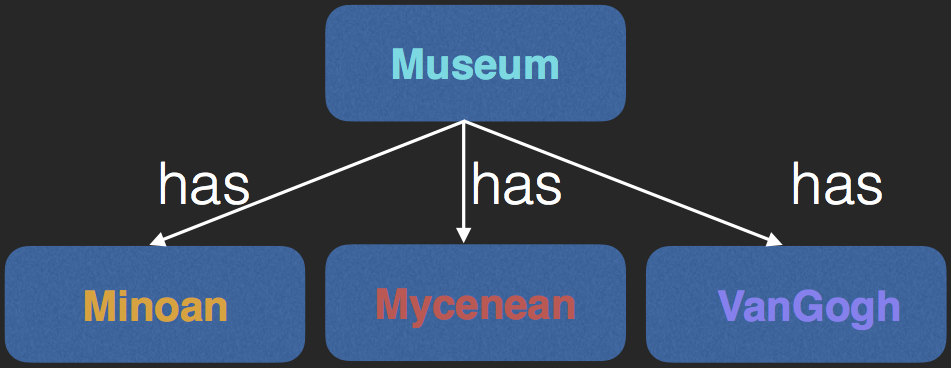
- Map ABox $A$ to $A'$ for scalability using $f$
$\begin{array}{l} C(a) \in A \implies C(f(a)) \in A'\\ R(a,b) \in A \implies R(f(a), f(b)) \in A' \end{array}$ - We choose concept sets as f
J. Dolby, A. Fokoue, A. Kalyanpur, A. Kershenbaum, E. Schonberg, K. Srinivas, L. Ma
Scalable Semantic Retrieval through Summarization and Refinement.
AAAI 2007
Scalable Semantic Retrieval through Summarization and Refinement.
AAAI 2007
Example Summary ABox $A'$
Pointer Analysis Analogy
class Cell {
private Object datum;
Cell(Object d) { datum = d; }
static void catInTheHat() {
Cell x = new Cell("Thing 1");
Cell y = new Cell("Thing 2");
}
}
Heap

Type-Based Abstraction

Example Query
- "Museums that have works from Crete"
- Answer is Heraklion since has Minoan LaParisienne
- DL
- $Museum \wedge \exists{has.\exists{creationSite.Crete}}$
- Negate query at each node, find contradictions
- Entities, edges in contradiction called justification
- Needs DL reasoning: creationSite edge is implicit
Initial Query Answer
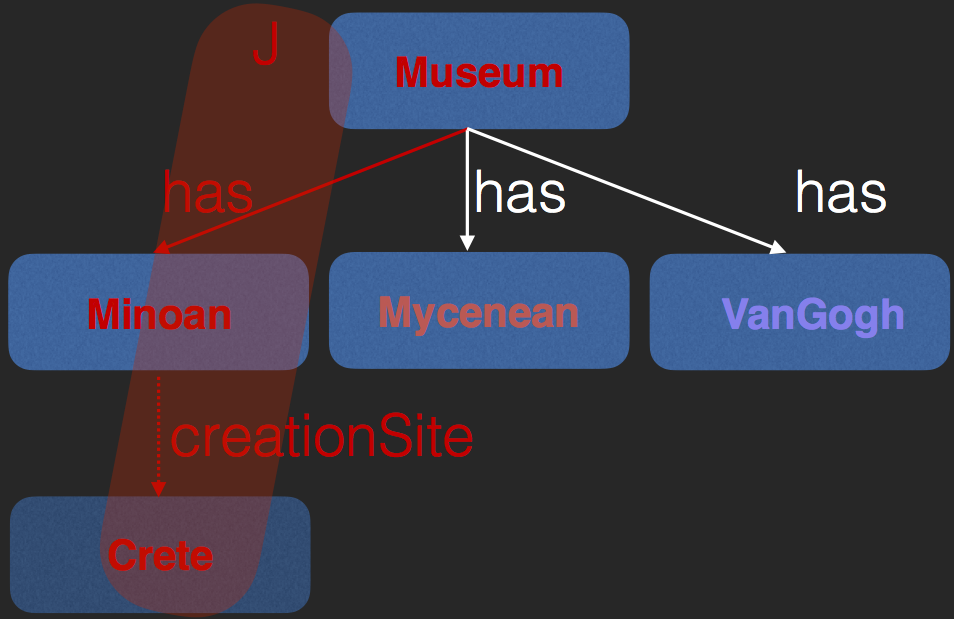
Refinement
- J is the justification, i.e. the conflict
- Partition summary nodes by edges in justification
$key(a) \equiv \left\{ R(s, t) \left| \begin{array}{l} f(a) = s \wedge\\ R(s,t) \in J \wedge\\ \exists b \; R(a,b) \in A \wedge f(b) = t \end{array} \right. \right\}$
Query Refinement
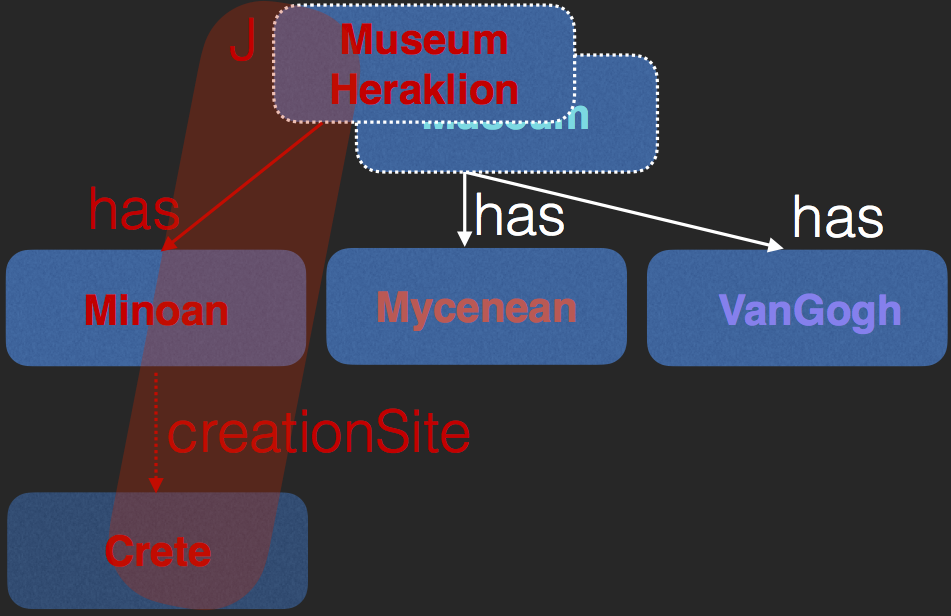
Refined Query Answer
Pointer Analysis Analogy
class Cell {
private Object datum;
Cell(Object d) { datum = d; }
static void catInTheHat() {
Cell x = new Cell("Thing 1");
Cell y = new Cell("Thing 2");
}
}
- Pointer analyis query: “what points to ‘Thing 1’?”
- refinement in the style of Plevyak or Sridharan

Reasoning Results
$${\scriptsize \begin{array}{|l|l|l|l|l|l|} \hline Reasoner & Dataset & Avg. Time & St.Dev & Range \\ \hline KAON2 & UOBM1 & 20.7 & 1.2 & 18-37\\ \hline KAON2 & UOBM10 & 447.6 & 23.3 & 414.8-530\\ \hline SHER & UOBM1 & 4.2 & 3.8 & 2.4-23.8\\ \hline SHER & UOBM10 & 15.4 & 25.6 & 6.4-191.1 \\ \hline SHER & UOBM30 & 34.7 & 63.5 & 11.6-391.1 \\ \hline \end{array}}$$RDF in a Relational Store
- Numerous large RDF data sources
- DBPedia (>300M triples)
- Web data (>3B triples from BTC)
- Exploit scalable RDBMS technology
- query optimization
- transaction support
- concurrency
- Quetzal
- https://github.com/Quetzal-RDF/quetzal
- Loosely-derived code in DB2 v10.1
M. Bornea et al., Building an efficient RDF store over a relational database. SIGMOD 2013
Museums with Locations

Quetzal Schema
- Entity-oriented schema
- properties for subject on single row
- rows for predicates and values
- secondary table for multi-valued predicates
- Fit entities onto limited database rows
- generally more predicates than available rows
- graph coloring to maximize density
- spill onto multiple rows only when necessary
- Analogous tables for reverse direction
- Reduces joins for "star" queries
Example Entity-Oriented Table
${\tiny \begin{array}{|r|l|l|l|l|l|l|}\hline {\rm{subject}} & {\rm{p1}} & {\rm{v1}} & {\rm{p2}} & {\rm{v2}} & {\rm{p3}} & {\rm{v3}}\\ \hline LaParisienne & type & Minoan & & & &\\ DeathMask & type & Mycenean & & & &\\ StarryNight & type & VanGogh & & & &\\ Heraklion & type & Museum & has & La\dots & at & l1\\ Athens & type & Museum & has & De\dots & at & l2\\ MOMA & type & Museum & has & St\dots & at & l3\\ l1 & type & Location & lat & 35.3 & long & 25.1\\ l2 & type & Location & lat & 38.0 & long & 23.7\\ l3 & type & Location & lat & 40.7 & long & -74.0\\ \hline \end{array}}$Register Allocation Analogy
- code fragment
var x = 7
var y = x + 7
var z = 3
y = y + z
| code | reg 1 | reg 2 |
x = 7 |
x | |
y = x + 7 |
x | y |
x = 3 |
z | y |
y = y + z |
z | y |
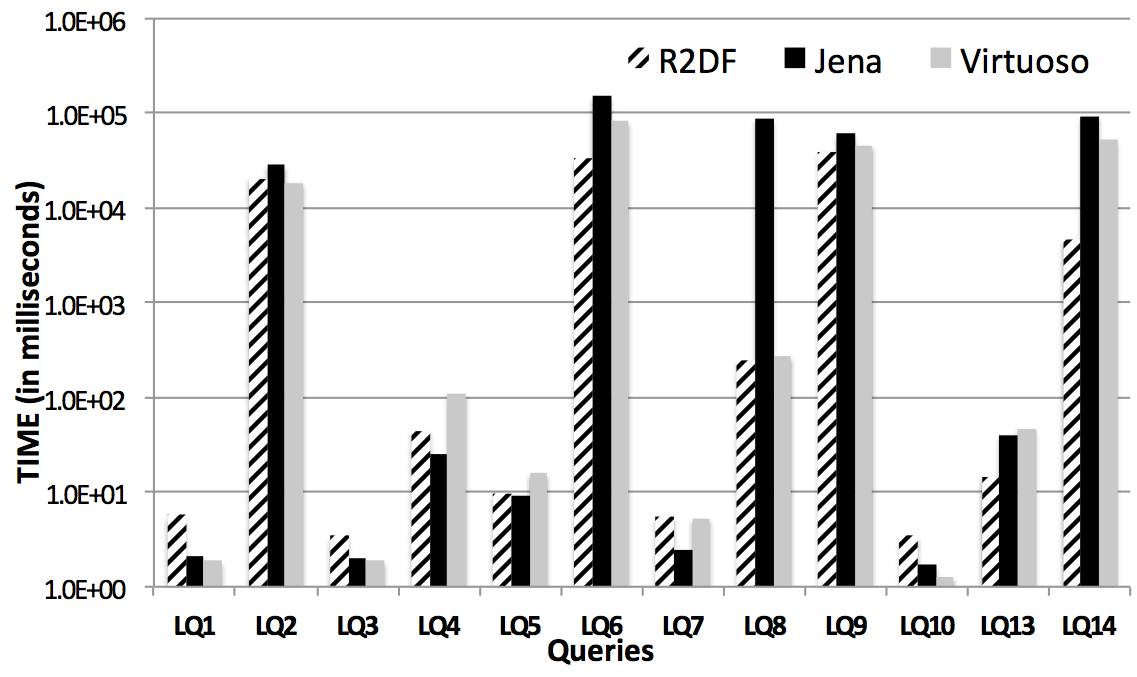
Quetzal Results on LUBM
Data Everywhere
- Numerous structured data sources available
- medical (Drugbank, Uniprot); general (DBpedia)
- much data in RDF, queried with SPARQL
- But data increasingly diverse
- RDF, XML, JSON, CSV formats
- accessible as dumps, query endpoints and APIs
- Powerful if integrated and queried effectively
- reuse and extend existing declarative SPARQL
J. Dolby et al., Extending SPARQL for Data Analytic Tasks. ISWC 2016
Modularize SPARQL with Functions
- "museums with some type of exhibit"
function museumsWith(?type ->
?museum ?lat ?long) {
?museum has ?art .
?art type ?type .
?museum at ?loc .
?loc geo:lat ?lat .
?loc geo:long ?long .
}
bind ?museum ?lat ?long as museumsWith(Minoan) .
Web Service http://ip-api.com/
- Web service returns IP-based information
<query> <status><![CDATA[success]]></status> <country><![CDATA[United States]]></country> <countryCode><![CDATA[US]]></countryCode> <region><![CDATA[IL]]></region> <regionName><![CDATA[Illinois]]></regionName> <city><![CDATA[Chicago]]></city> <zip><![CDATA[60605]]></zip> <lat><![CDATA[41.8632]]></lat> <lon><![CDATA[-87.6198]]></lon> <timezone><![CDATA[America/Chicago]]>&</timezone> <isp><![CDATA[AT&T Services]]></isp> <org><![CDATA[Hilton Hotels Corporation]]></org> <as><![CDATA[AS7018 AT&T Services, Inc.]]></as> <query><![CDATA[12.218.232.8]]></query> </query>
Web Service Example
- Web service to return latitude and longitude
function geo:getPosition( -> ?lat ?long) service get http://ip-api.com/xml [] -> xml "/query": "./lat" "./long"
getPosition used with bind
select ?lat ?long where {
bind ?lat ?long as geo:getPosition()
}
Combining Disparate Data
- "Nearby Minoan exhibits"
- RDF museums,
http://ip-api.comlocations
select ?museum where {
bind ?museum ?lat1 ?long1
as museumsWith(Minoan) .
bind ?lat2 ?long2 as geo:getPosition()
FILTER(?lat2-?lat1 < .1 &&
?long2-?long1 < .1)
}
The Future
- Further extensions to SPARQL
- further modularization, e.g. module systems
- potential for first-class functions
- Semantic big data means reasoning
- put summarization, refinement into Quetzal
- exploit entity-oriented schema for summarization
- Would love others to get involved